
Measuring the similarity between documents has been extensively applied in various domains. Automated matching between CV and job description is widely adopted by recruitment sector for example. Recently, more attentions have been paid on measuring the similarity between two very short segments of text (on sentence level or phrase level).
However, the problem of short text similarity raises new challenges. Due to the short length, traditional distance measure approaches like Cosine similarity may not work any more. For example, “apple tree” and “Apple computer” have a high Cosine similarity, but they describe totally different things.
Moreover, it also becomes more difficult to eliminate ambiguity of short text when not enough context is provided, and thus corpus-based similarity measures would be less effective either.
To address these difficulties, Argsen has developed a powerful tool to check the semantic similarity between phrases. Following table shows the similarity score of some toy examples returned by several popular online tools as well as our own. And didn’t we do so well? ☺︎
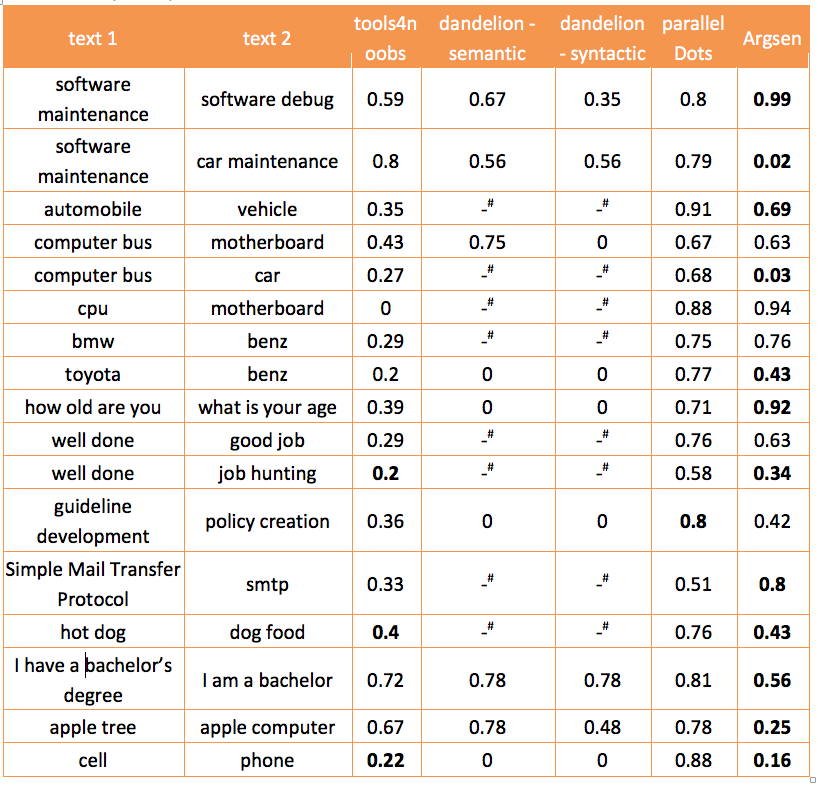
–#: Error. It fails to identify the language.
Bold text means that the result is significantly better than others.