Artificial Intelligence is a hot topic across industries. Suddenly everybody is discussing AI applications. The reality is that the entry barrier to AI modelling is so low and any programmers and data analysts can develop AI algorithms. With sufficient amount of training data, the result is likely to be called “mostly accurate”.
However, there is an important lesson that AI training courses or vendors will choose not to tell. While the quality of AI models is benchmarked, the “mostly accurate” result is provided at an aggregated level. In the real world, 95% vs 5% accuracy makes little differences as the individual prediction run is either correct or wrong. For example, if an AI model classifies your resume and classified incorrectly, despite that the overall accuracy is 99%. You are still disadvantaged and will certainly complain. The result of this will cascade to higher-levels and influence other users (they don’t know whether their result is correct or not). At the end, nobody trusted the system based on a biased perception.
McKinsey has a similar view. Their report (https://www.mckinsey.com/featured-insights/artificial-intelligence/ai-adoption-advances-but-foundational-barriers-remain) suggested that one barrier to AI adoption is that human may override the AI decisions.
At the end of day, the success measure of AI should not be on how well the algorithm is benchmarked, but rather on how well the result is accepted. This requires a process-oriented approach in the solution development.
Training Data quality
Recently Argsen is working on a project which requires a text comparison component (by semantic meaning). In order to speed up the development process, we have explored both commercial and open source APIs for their suitability in our product. Simultaneously, we have trained our models. I am not going to discuss the result here. In the IT hardware world, there is no bad hardware but only inadequately priced hardware. Similarly, in AI world, there is no bad model, but only models not fitting for the purpose.
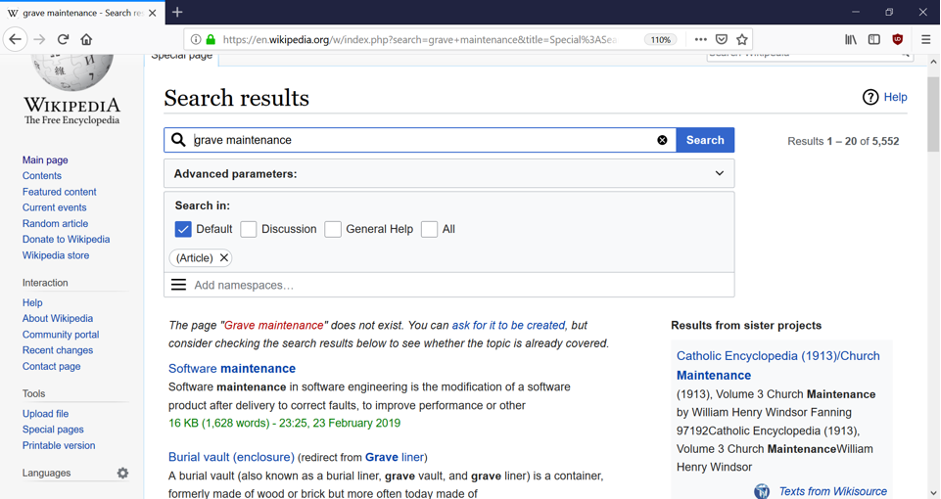
Here are some examples: “software maintenance” and “grave maintenance”; “software debug” and “software maintenance”. Obviously, the first set should return low similarity and the second one should return a high similarity score. Unfortunately, many models cannot give correct results in both cases.
Semantic comparison is based on context. Most models are built as word vectors. Therefore, we picked some models, which we can access the training data to look for the underlying causes. Now things get interesting. The model that matches “grave maintenance” and “software maintenance” is sourcing the explanation / context from Wikipedia. When search “grave maintenance” on English Wikipedia, the term does not exist and “software maintenance” becomes the first possible match. Given the same text used in the training mode, the model gives a very high score when comparing two terms.
I guess some people will say that such errors can be ruled out during the ongoing tagging / training. While I acknowledge that it is possible, it really affects the end-user experience. I also doubt how much human effort has been put to clean the training data sets, especially with those complex models. More importantly, without the ability accessing to the original training data sets, it is almost impossible to understand the root causes.
Just need to be cautious when using third-parties models.